Inhabited Design, a Skill for the AI Slop Site Problem
The Stanford AI Index 2026[1] recently indicated that more than 50% of web articles are now AI generated. The same is likely true of the new web apps I see on the regular, whether on Show Hacker News, Reddit, or Product Hunt.
Purple gradients are the em dashes, three-column CTAs are the ‘load-bearing claim’, and rounded pills the ‘it’s not X, it’s Y’ of the AI Slop Site.
As a creator of side projects, the last thing you or I want is for our project site to look sloppified — just as we avoided the Bootstrap look in the early 2010s, Material Design in the late 2010s, and Tailwind CSS in the early 2020s.
The result of my experiments is a Claude Code skill (inhabited-design) that creates unique and delightful front-end designs anyone can use; the rest of this post is what I learned along the way.
Slop Attractors and the Personas that Escape Them
Given that LLMs are trained on the entire corpus of human knowledge, why do they always produce the same slop?
There are some hypotheses on why: cycles of LLM output attractors[2], model collapse[3], and image generation converging even from different initial prompts[4]. But suffice to say this is a well-observed phenomenon — models are trained or refined to produce the same set of outputs for a given input, despite their stochastic nature.
This is not a bad thing. When we ask an LLM for the output of ‘2+2’, we do not want a creative answer from ‘creative math’.
The very first idea that came to mind came from old movie director commentaries and design documentaries — good artists borrow, great artists steal. Plus, the good designers I know are never designing from scratch; they keep a notebook full of inspirations, similar items, and sometimes even a pegboard.
It’s one thing to ask AI to take on the persona of a ‘world expert designer’, it’s another to ask it to ‘take on the persona of a particular famous designer who designs X with references Y and Z’. Those design inspirations also serve as extra points of perturbation, to hopefully nudge us away from the attractors.
While research on personas for logic / reasoning tasks[5] indicates they do not improve model performance, a few studies suggest personas do help with creative and open-ended tasks[6][7][8].
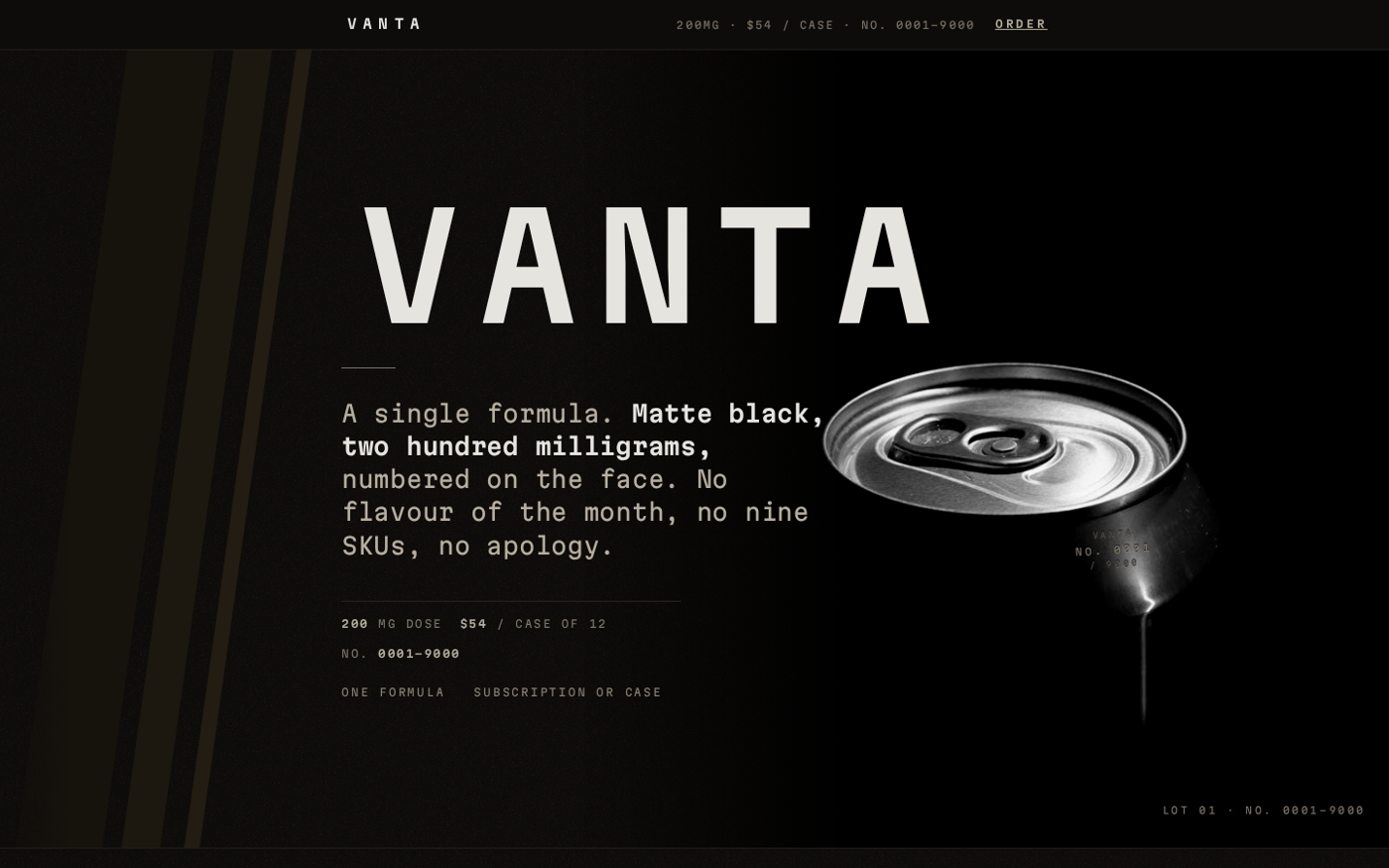
The example at the top of this article is VANTA, an energy drink pitched at finance types, with Peter Zumthor as the inhabited designer — a matte-black numbered allotment with a serial struck into the metal, its restraint sampled from an AmEx Centurion card and a hanok teahouse rather than from yet another glowing can.
Visual Verification and Self Refinement
Next, treating the feedback process like a code review step, I want the AI to self-refine[9] toward better, more delightful output.
But what does better and more delightful mean here?
An old saying comes to mind: “Specificity is the soul of good writing.” Instead of grading the design by a generic ‘world class designer’, why don’t we create a hyper-specific persona — the ideal customer profile (ICP) of the site? Then we can run the self-refine loop against that ICP until it converges.
We can also turn that qualitative score into a quantitative one with heuristic Quantitative LLM Judges[10], scoring along the axes of usability, flair, personality, visual design, originality, visual impressiveness, and most importantly, ‘the wow factor’.
And lastly, while LLMs are used to ingesting tokens, we are ultimately still talking about a visual medium — so let’s use multimodal LLMs to actually inspect the visual output of the designer, which is proven to produce better critiques[11].
Verbalized Sampling and IFG
We get better results at this stage, but running the same prompts repeatedly still draws from a small collection of designers and the same set of inspirations.
To combat this we inject actual randomness into the design pipeline. To get a designer that’s both fitting and varied, we run Verbalized Sampling[12] over a long list the LLM generates, then draw one with a Python script.
And to keep that pool from collapsing into the same Swedish-modern designers every time, we borrow from Intent Factored Generation[13] so the candidates stay varied.
Here is what it looks like in practice. When picking a designer to inhabit, the LLM first generates a pool of 20 candidates across 10 factors (Graphic, Film, Craft, Fine Art, and so on) appropriate for the site, then calls a Python script to sample one of the 20 uniformly — which is how we got Peter Zumthor for VANTA.
We do the same for design frame, constraint, competitors, domain, typography, and inspiration, building a mad-lib of design inputs unique to our particular site. You can step through the full VANTA pipeline — every input with its millisecond seed and the reason it was drawn.
All of this generates the initial site design, which then iterates to convergence against our ICP — a final design that is both varied and wow-worthy.
Output Comparison
Here is the same brief — let’s create a landing page for an energy drink targeting finance bros — run a few ways. First, a single one-shot pass from Claude Code’s built-in frontend-design skill:
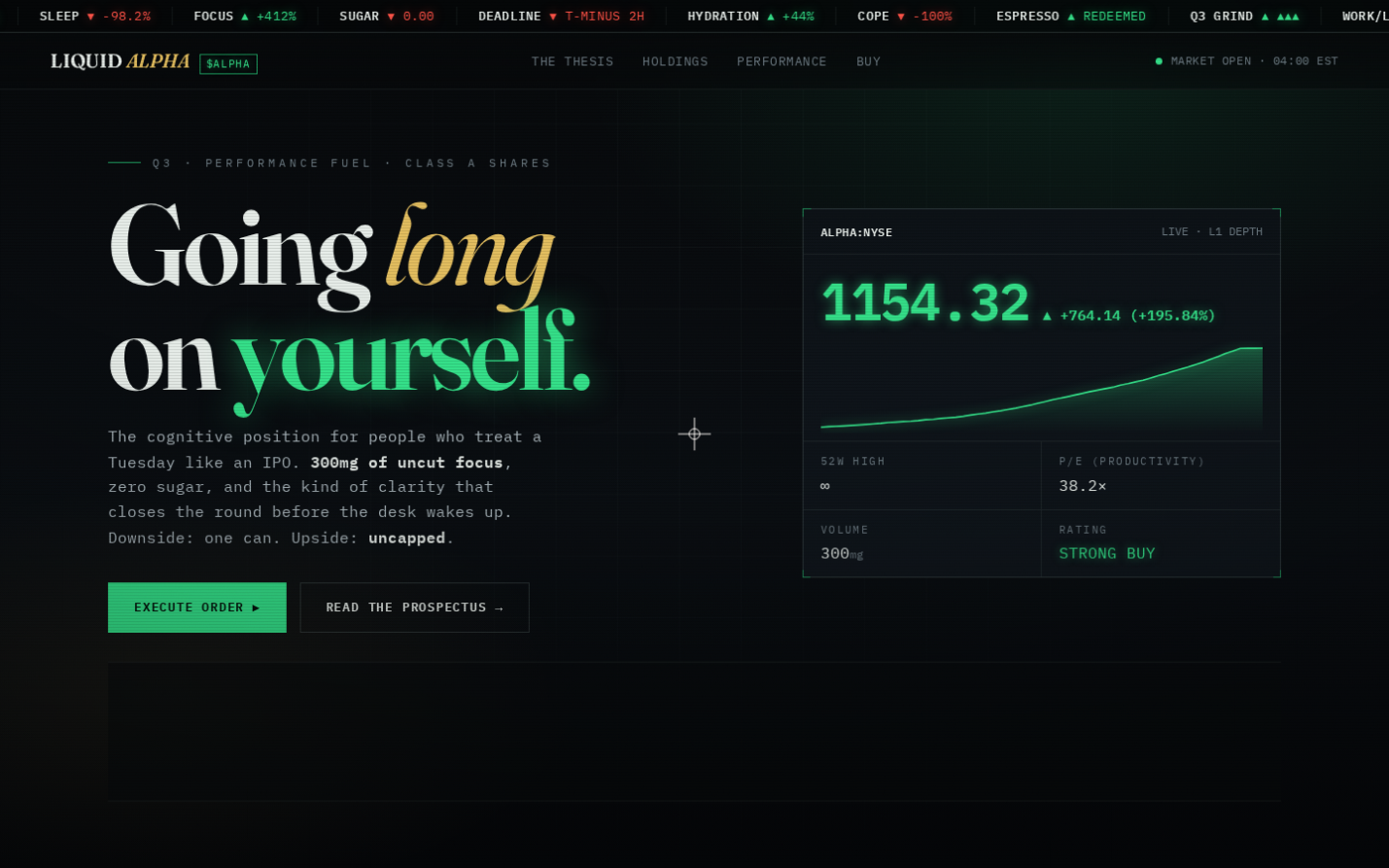
Then Lovable’s take on the same brief, with no skill in the loop at all:

Both land on the exact same attractor — the near-black hero, the green glow, the giant wordmark, the STRONG BUY / stock-ticker furniture. Against them, the VANTA page at the top of this post: same brief, same model, but a matte-black numbered allotment that converged at 70/70 (ten points on each of seven axes) against its own in-character reader.
Now you might think ‘this is a lot of tokens for a simple site design’, and you would be correct. The skill could use some simplification, but my experience shows that unique design is expensive.
I’ve come to appreciate how much “AI thought” actually goes into producing a unique, non lowest-common-denominator AI Slop. You can give the skill a try on GitHub or see it in action on the inhabited-design page today — or take the principles and lessons with you to build the next great ‘software architect’, ‘system design’, or ‘research innovation’ skill.
References
- Stanford Institute for Human-Centered AI. (2026). The 2026 AI Index Report. Stanford HAI. hai.stanford.edu/ai-index/2026-ai-index-report
- Wang, Z., et al. (2025). Unveiling Attractor Cycles in Large Language Models: A Dynamical Systems View of Successive Paraphrasing. arXiv:2502.15208. arxiv.org/html/2502.15208v1
- Shumailov, I., et al. (2024). AI models collapse when trained on recursively generated data. Nature. nature.com/articles/s41586-024-07566-y
- Hintze, A., Proschinger Åström, F., & Schossau, J. (2026). Autonomous language-image generation loops converge to generic visual motifs. Patterns, 7(1), 101451 (Cell Press). cell.com/patterns/fulltext/S2666-3899(25)00299-5
- Zheng, M., et al. (2023). When “A Helpful Assistant” Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models. arXiv:2311.10054. arxiv.org/abs/2311.10054
- Salewski, L., et al. (2023). In-Context Impersonation Reveals Large Language Models’ Strengths and Biases. arXiv:2305.14930. arxiv.org/pdf/2305.14930
- Wan, Y., et al. (2025). Diverse AI Personas Can Mitigate the Homogenization Effect in Human-AI Collaborative Ideation. arXiv:2504.13868. arxiv.org/pdf/2504.13868
- Licato, J., et al. (2025). Do Persona-Infused LLMs Affect Performance in a Strategic Reasoning Game? arXiv:2512.06867. arxiv.org/html/2512.06867v1
- Madaan, A., et al. (2023). Self-Refine: Iterative Refinement with Self-Feedback. arXiv:2303.17651. arxiv.org/pdf/2303.17651
- Sahoo, A., et al. (2025). Quantitative LLM Judges. arXiv:2506.02945. arxiv.org/html/2506.02945v2
- Li, Y., et al. (2025). ReLook: Vision-Grounded RL with a Multimodal LLM Critic for Agentic Web Coding. arXiv:2510.11498. arxiv.org/pdf/2510.11498
- Zhang, J., et al. (2025). Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity. arXiv:2510.01171. arxiv.org/pdf/2510.01171
- Ahmed, E., et al. (2025). Intent Factored Generation: Unleashing the Diversity in Your Language Model. arXiv:2506.09659. arxiv.org/pdf/2506.09659
Citation
@article{zhang2026inhabited,
author = {Zhang, Shimin},
title = {Inhabited Design, a Skill for the AI Slop Site Problem},
year = {2026},
month = {06},
day = {21},
howpublished = {\url{https://shimin.io}},
url = {https://shimin.io/journal/inhabited-design/}
}